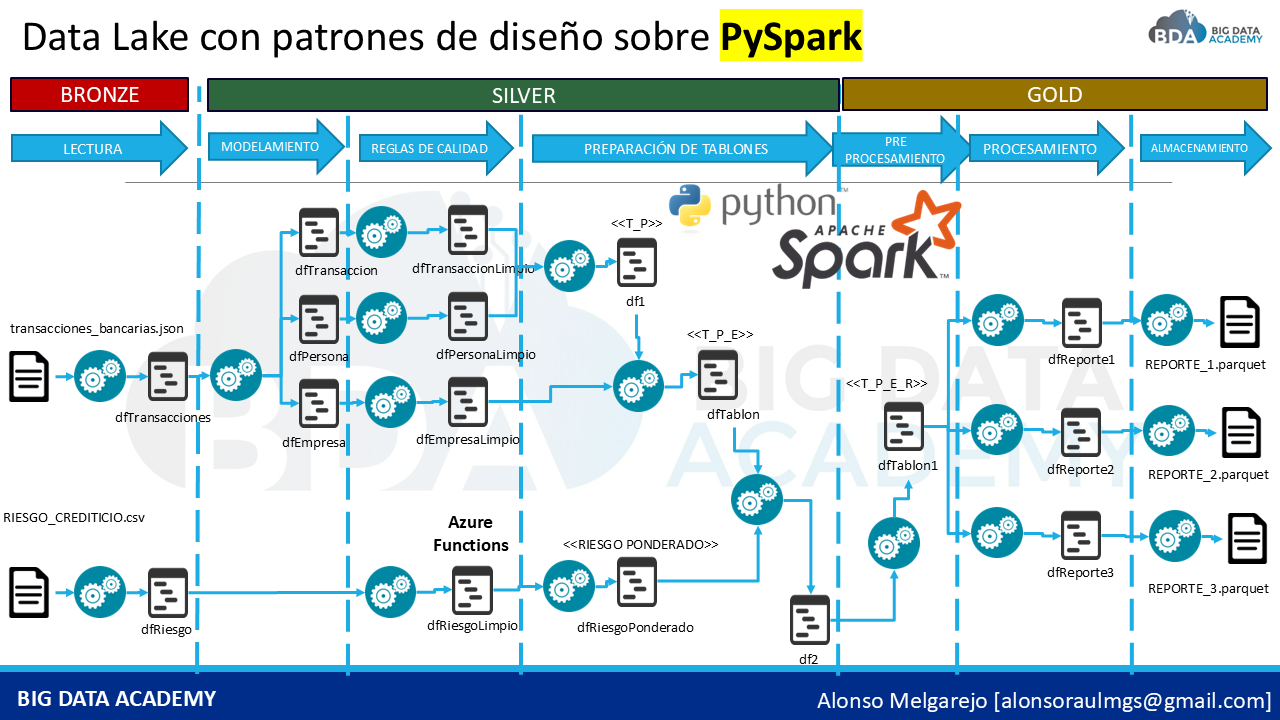
En el mundo del BIG DATA, no basta con procesar datos: es fundamental AUTOMATIZAR y optimizar los pipelines de información. En este curso, aprenderás a diseñar workflows escalables de ingeniería de datos utilizando PYSPARK, aplicando buenas prácticas para estructurar procesos robustos capaces de ejecutarse en entornos MULTI-CLOUD y ON-PREMISE, asegurando eficiencia y control en el procesamiento de grandes volúmenes de información.
El MONITOREO del procesamiento distribuido es clave para garantizar calidad y rendimiento en proyectos de datos. Aprenderás a estructurar pipelines confiables mediante particionamiento, optimización de consultas y control de ejecución en arquitecturas DATA LAKE y Lakehouse. Un pipeline bien diseñado permite detectar cuellos de botella, optimizar recursos y asegurar consistencia en los resultados analíticos.
Además, conocerás cómo organizar proyectos de INGENIERÍA DE DATOS siguiendo buenas prácticas profesionales, permitiendo reutilizar código, mantener trazabilidad de los procesos y facilitar la evolución de soluciones analíticas en entornos empresariales. La correcta estructuración de PIPELINES permite mejorar la calidad de los datos y asegurar procesos confiables para analítica avanzada y machine learning.
El procesamiento de datos no es solo ejecución de código, es diseño de arquitectura, optimización de recursos y CONTROL de cada etapa del flujo de información. Si buscas desarrollar habilidades alineadas a entornos empresariales modernos, dominar PYSPARK y el diseño de pipelines distribuidos es un paso fundamental para crecer profesionalmente en el mundo del Data Engineering.
¿Y cómo puedo aprender todo esto? 👇














