En un mundo donde los DATOS crecen de forma exponencial, saber procesar grandes volúmenes de información de manera eficiente marca la diferencia. Con tecnologías como PYSPARK y SPARK SQL, es posible transformar datos en conocimiento útil mediante procesamiento distribuido. Desde la integración de múltiples fuentes hasta la generación de datasets optimizados para analítica avanzada, el Data Engineering está redefiniendo la forma en que las organizaciones toman decisiones.
Automatizar PIPELINES DE DATOS no es solo una tendencia, sino una necesidad en organizaciones que manejan grandes volúmenes de información. Las arquitecturas modernas utilizan Data Lakes, Delta Lake y procesamiento paralelo para optimizar tiempos de ejecución y mejorar la calidad de los datos disponibles para análisis. Estas soluciones permiten procesar millones de registros de manera eficiente en entornos MULTI-CLOUD y ON-PREMISE.
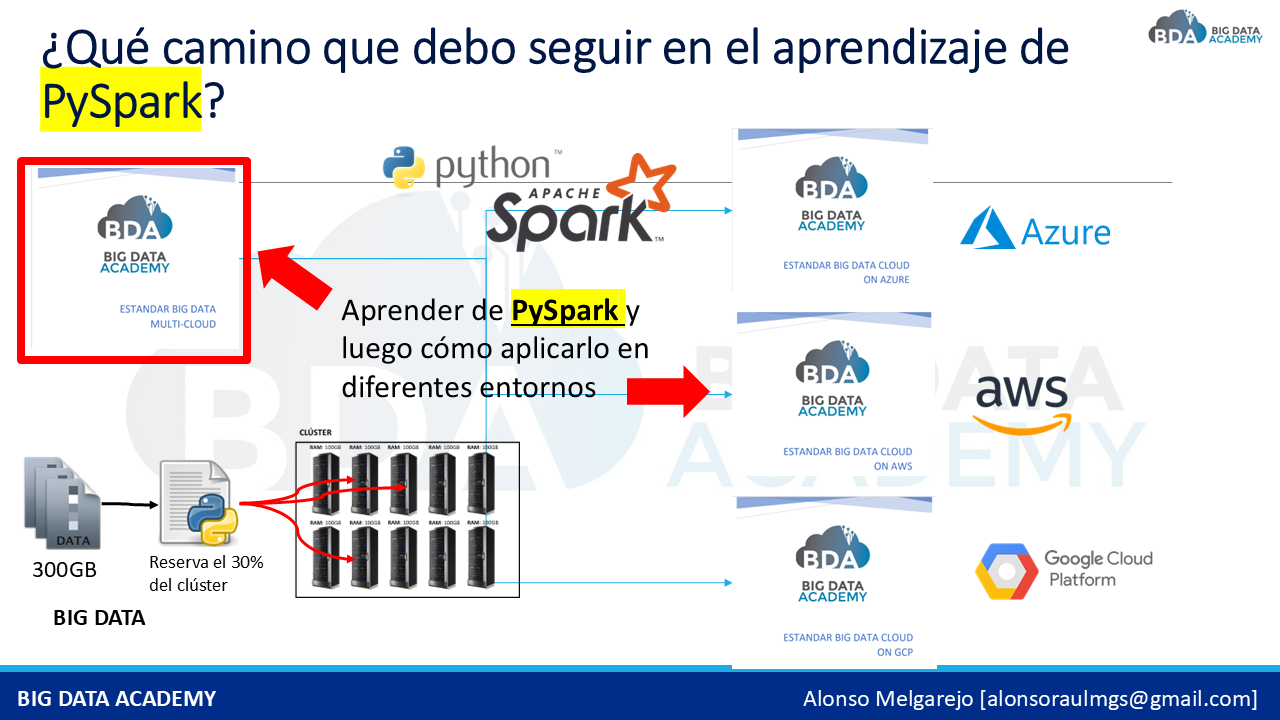
El verdadero valor está en combinar herramientas de procesamiento distribuido con arquitecturas escalables. Con PySpark, es posible construir soluciones que integren múltiples fuentes de datos, optimicen recursos y reduzcan costos operativos. Estas tecnologías permiten desarrollar pipelines reutilizables que pueden ejecutarse en AWS, AZURE, GCP o entornos ON-PREMISE profesionales, evitando dependencia de un proveedor específico.
No se trata solo de teoría, sino de APLICACIÓN PRÁCTICA. Nuestro curso está diseñado para que trabajes con escenarios reales de ingeniería de datos, desarrollando soluciones completas que simulan entornos empresariales. Al finalizar, tendrás la capacidad de implementar pipelines de datos escalables y aportar valor en proyectos de analítica avanzada, inteligencia de negocio y machine learning.
¿Y cómo puedo aprender todo esto? 👇














