En un mundo impulsado por los DATOS, las empresas buscan soluciones que permitan procesar información de manera eficiente y escalable. Con herramientas como PYSPARK y SPARK SQL, es posible automatizar el procesamiento de grandes volúmenes de datos, mejorar la toma de decisiones y generar valor a nivel empresarial. La clave está en saber aplicar estas tecnologías de manera estratégica para obtener resultados concretos.
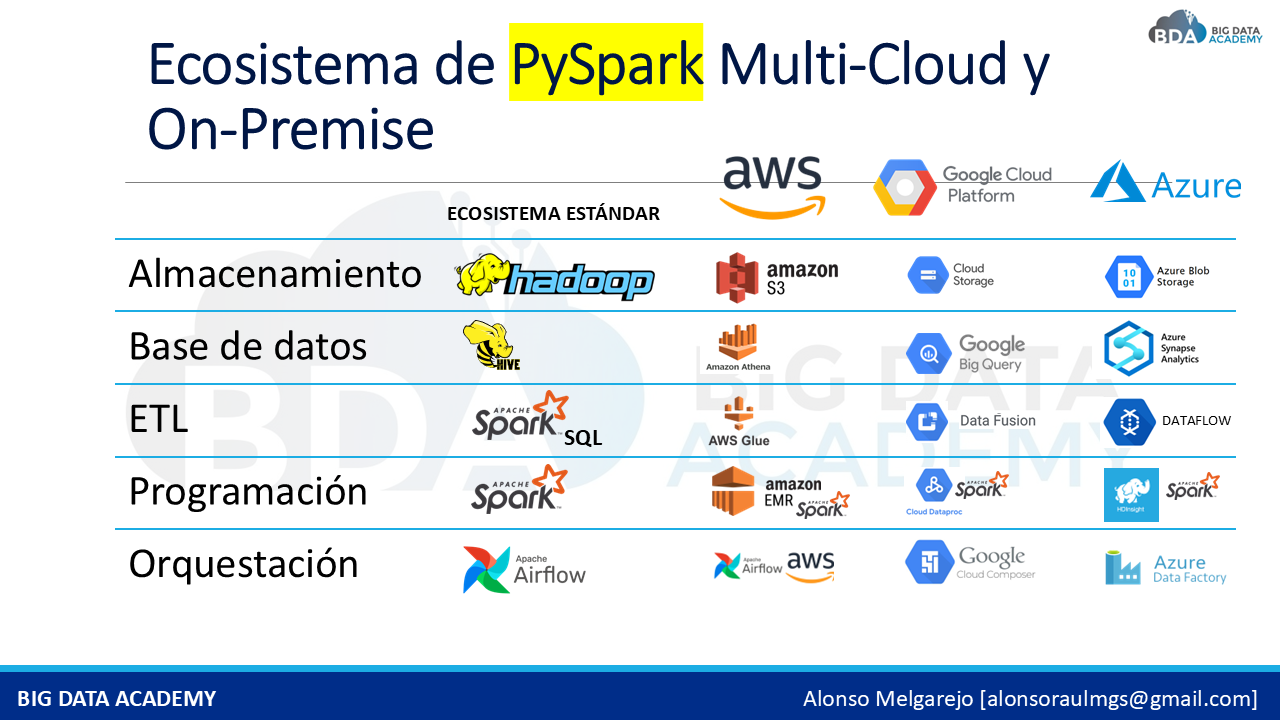
Aprovechar arquitecturas modernas como DATA LAKES y LAKEHOUSE permite organizar grandes volúmenes de información de forma estructurada y accesible. Las empresas utilizan PySpark para procesar millones de registros en minutos, aplicando paralelización y optimización de recursos en entornos MULTI-CLOUD y ON-PREMISE. Dominar estas herramientas no solo mejora la eficiencia técnica, sino que abre puertas a nuevas oportunidades en el mercado laboral.
El futuro del DATA ENGINEERING está en el procesamiento distribuido. Desde la transformación de datos hasta la integración de múltiples fuentes, el dominio de PYSPARK permite optimizar flujos de trabajo y construir pipelines robustos preparados para escenarios empresariales reales. Las organizaciones que implementan estas soluciones logran mejorar su eficiencia operativa y su capacidad de análisis.
Aprender a utilizar estas tecnologías es fundamental para quienes buscan destacar en la industria tecnológica. Con el conocimiento adecuado, es posible desarrollar SOLUCIONES ESCALABLES sin necesidad de depender de herramientas propietarias, aplicando estándares modernos de arquitectura de datos.
¿Y cómo puedo aprender todo esto? 👇














