Muchos profesionales se enfocan en aprender herramientas, pero olvidan lo más importante: el ENFOQUE EMPRESARIAL. Comprender cómo se estructuran los proyectos en la nube, qué decisiones tomar desde el INICIO y cómo diseñar arquitecturas modernas puede marcar la diferencia entre una solución casera y una que impacte el negocio. Lo que parece básico es en realidad FUNDAMENTAL: roles, flujos de trabajo, tipos de proyectos, y una visión clara de cómo el dato viaja desde su origen hasta la decisión final.
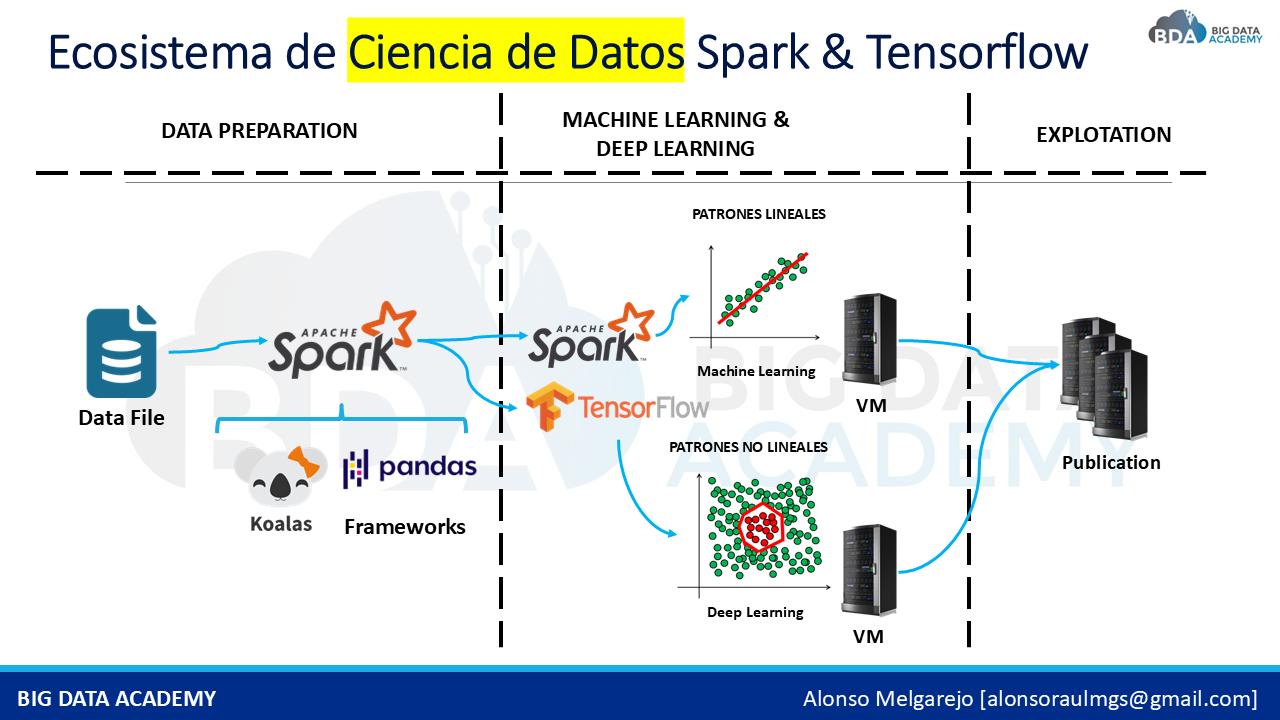
La PREPARACIÓN de datos sigue siendo una de las etapas más críticas dentro de cualquier proyecto analítico. Limpiar registros, transformar variables, detectar inconsistencias y construir datasets optimizados para Machine Learning y Deep Learning es parte fundamental del trabajo. Herramientas como PYSPARK permiten procesar grandes volúmenes de información utilizando procesamiento distribuido, acelerando el desarrollo de soluciones escalables y reutilizables.
Entender cómo integrar SPARK, PANDAS y TENSORFLOW dentro de un mismo flujo analítico permite construir pipelines mucho más eficientes y preparados para producción. No se trata solo de entrenar modelos, sino de comprender cómo organizar datos, automatizar procesos y optimizar arquitecturas para que los resultados puedan escalar dentro de una empresa.
Cada decisión que tomas al inicio de un proyecto de Ciencia de Datos afecta todo lo que viene después. Por eso, es clave entender cómo diseñar pipelines reutilizables, cómo preparar datos para Machine Learning, y cómo aplicar conceptos sólidos de la nube desde el primer paso. No se trata de hacer modelos, sino de que esos modelos funcionen, escalen y generen RESULTADOS. Todo esto lo puedes dominar incluso si partes DESDE CERO.
¿Y cómo puedo aprender todo esto? 👇














