Es común que cuando estés programando tus procesos trabajes en un entorno como tu laptop local que puede tener 16GB de RAM.
En la etapa de desarrollo tus procesos funcionan muy bien por que trabajas con poca volumetría, pero CUANDO HACES EL PASE A PRODUCCIÓN ESTOS TERMINAN COLAPSANDO, ya que la volumetría excede la memoria RAM de tu laptop.
Esto clásicamente se solucionaba usando un servidor, simplemente poníamos un server con mucha potencia, por ejemplo podría tener 100GB de memoria RAM, de esta manera podíamos soportar volumetrías mucho más grandes, pero los servidores también tienen límites.
UNA MANERA EN CÓMO LAS EMPRESAS SOLUCIONABA ESTO de forma clásica era usar un clúster de varios servidores, por ejemplo teniendo 10 servidores de 100 GB de RAM cada uno, tendríamos una potencia computacional de 1000 GB de RAM, de esta manera teníamos mucha potencia computacional para procesar volumetría de cientos de gigas
Sin embargo, el proceso que has codificado tienes que ADAPTARLO PARA QUE DISTRIBUYA SU CARGA DE TRABAJO en cada uno de esos 10 servidores, el proceso por sí solo no hace la distribución, es algo que tú tienes que codificar y esto te toma mucho tiempo.
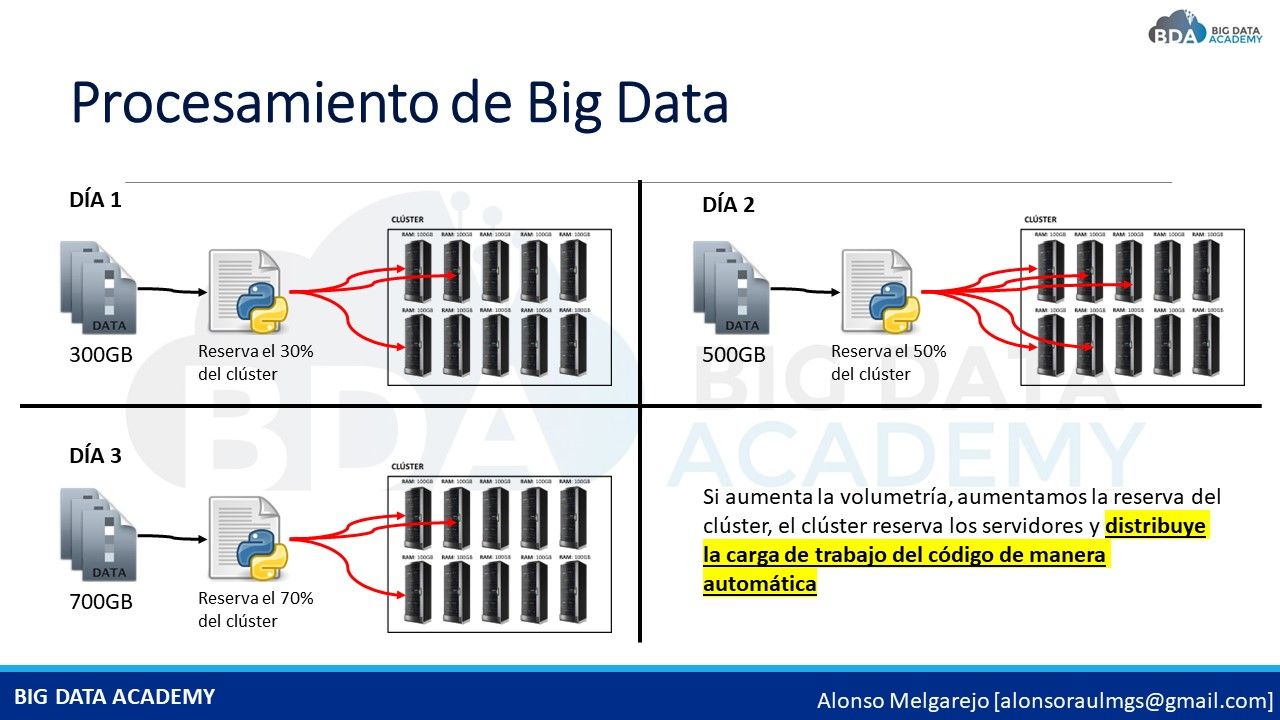
AQUÍ ES DONDE ENTRAN LOS CLÚSTERS DE BIG DATA, los cuales permiten distribuir de manera automática la carga de trabajo, por ejemplo supongamos que vienen 300 GB de volumetría, el proceso de Big Data tomará esos 300 GB y los distribuirá entre los 10 servidores del clúster, si al día siguiente vienen 500 GB, el proceso de Big Data también los distribuirá de manera automática entre los 10 servidores
Gracias a esto puedes enfocarte sólo en codificar tu proceso y no invertir tiempo en codificar cómo distribuir la carga de trabajo
¿CÓMO PUEDES APRENDER TODO ESTO?















